A hardware-focused algorithm that uses less energy and has a smaller memory footprint must be considered.
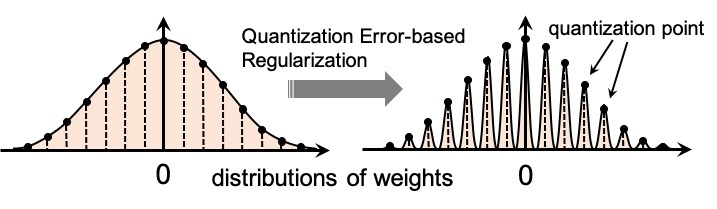
Although quantized neural networks reduce computation power and resource consumption, it also degrades the accuracy due to quantization errors of the numerical representation, which are defined as differences between original numbers and quantized numbers. We proposed “QER,” a solves such the problem by appending an additional regularization term based on quantization errors of weights to the loss function. This technique can improve the inference accuracy without additional latency.