Deep neural networks have achieved human-level accuracy and have been widely accepted. The basis of their computation is the inner product between the input data that are acquired via sensors and the learned weight parameters. The rapid expansion and adoption of neural networks are attributable to the advance of computer engineering, which allowed the huge computation of the neural networks to be completed in acceptable time duration. Since the ever-evolving neural network algorithms are getting more and more complex, various dedicated and optimized accelerators for fast and efficient neural network processing have been researched.
In our lab, the researches for accelerator architectures with quantized neural network techniques that relax the computational and memory requirements, and for general-purpose neural network processors exploiting the natures that are commonly existing in various kinds of networks, as well as for the algorithms for achieving high efficiency and accuracy based on the hardware-aware computational structure, are conducted.
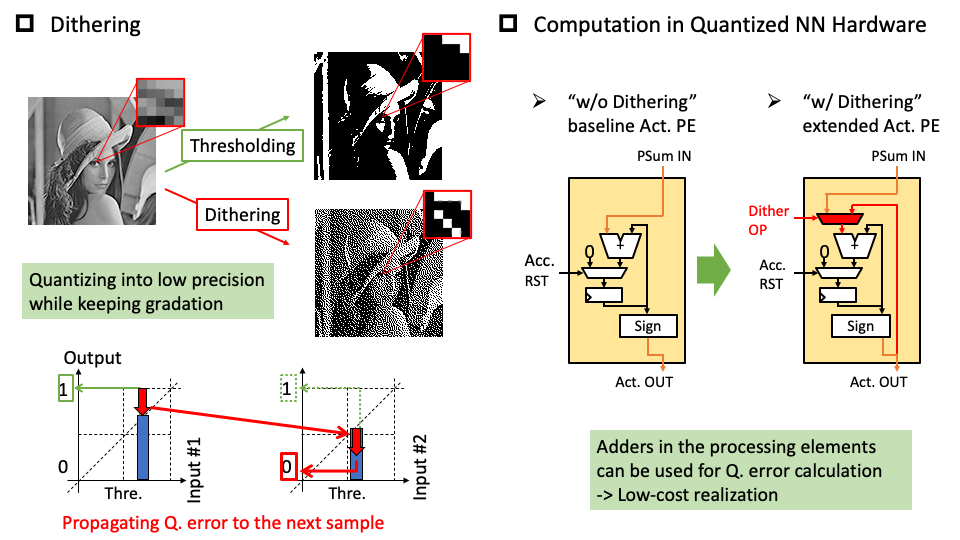
We presented an accelerator architecture named “BRein Memory,” which adopts the binary neural network to achieve high energy efficiency by storing all of the parameters in the on-chip SRAMs and completing the entire calculation in thin logic units near the SRAMs. We also proposed a quantized neural network algorithm “Dither NN” that improves the accuracy while the hardware costs are restrained, by utilizing dithering in quantized neural network processors.